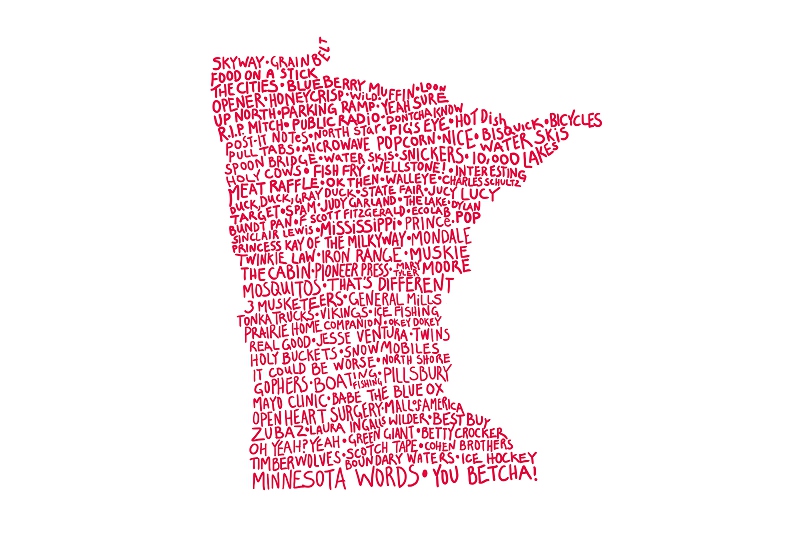
I learned a lot about Minnesota making this!

I learned a lot about Minnesota making this!
This is a great quote. I designed this in Inkscape.

This is a very complicated case, Maude. You know, a lotta ins, lotta outs, lotta what-have-you’s.

This is a series of medium sized posters I made to fit a bunch of colored frames
inspired by a sign that said “shipping dept”

First time I heard this was in Madagascar.

My pot of Gold’s my life with you. Quote from Robby Hecht, “Pot of Gold”
I have fielded data like this:
[u]OriginalName[/u]
Miller,John A
Jones,Sue
San Luis,Jose Gabriel
Luis-Gomez,Pepe
I want to parse this, giving special treatment to the right of the comma. I only need the first word in the first name. So we are going to be doing some Min and Instr to get where we need to go. The problem I had is that some of the Last Names have a space and some of the First Names do not have a space.
Here is the solution:
iif(InStr((InStr([OriginalName],”,”)+1),[OriginalName],” “)>1,Mid ( [OriginalName], InStr([OriginalName],”,”)+1, InStr((InStr([OriginalName],”,”)+1),[OriginalName],” “) – InStr([OriginalName],”,”)),Mid ( [OriginalName], InStr([OriginalName],”,”)+1, Len([originalname]) – InStr([OriginalName],”,”)))
Breaking it down…
First we look for a space after the comma
InStr((InStr([OriginalName],”,”)+1),[OriginalName],” “)>1
If we find a space we grab everything from the comma to the space
Mid( [OriginalName], InStr([OriginalName],”,”)+1,InStr((InStr([OriginalName],”,”)+1),[OriginalName],” “) – InStr([OriginalName],”,”))
If no space after the comma we grab from the comma to the end of the cell
Mid ( [OriginalName], InStr([OriginalName],”,”)+1, Len([OriginalName]) – InStr([OriginalName],”,”))
Let’s take a look at the blue and the orange. Notice that they are the same except for the part after the second comma. This is the “number of characters” variable.
Mid ( text, start_position, number_of_characters )
So the text and start position are the same for both blue and orange. It is only the “number of characters” variable which is different.
In the blue our number of characters is the Field Length minus the position of the comma.
Len([OriginalName]) – InStr([OriginalName],”,”)
The orange one is harder because here we need Position of First Space After Comma minus the position of the comma.
InStr((InStr([OriginalName],”,”)+1),[OriginalName],” “) – InStr([OriginalName],”,”)
So far, every time we have used InStr we have started at position zero. The start position is optional and we have not used it.
Instr ( [start], string_being_searched, string2, [compare] )
However, in this orange bit we need to use the start position variable and the value we want to use is equal to the position of the comma plus 1.

It’s not his fault, upon further investigation I found that certain legal writings are lousy with the term.
Here is the paragraph that started me on this investigation:

Williams v. Sprint/United Mgmt. Co., 230 F.R.D. 640, 655 (D. Kan. 2005)
In Williams v Sprint Judge Waxse cites an article from 1999:
Dean M. Harts, Reel to Real: Should You Believe What You See?, 66 Def. Couns. J. 514, 522 (1999)

Harts’ article was written in 1999. Perhaps the vernacular has changed since then. However, Ralph Losey used “hash mark” in 2007 in his paper Hash: The New Bates Stamp.

In this example Losey uses the phrase of his own accord but perhaps he got it from one of the two sources he cites:
U.S. District Court for the District of Maryland, Suggested Protocol for Discovery of Electronically Stored Information and Williams v. Sprint/United (same that I quote above).

U.S. District Court for the District of Maryland, Suggested Protocol for Discovery of Electronically Stored Information
Then I find a book, written in 2009 that quotes Sprint but does not independently use “hash mark.” Discovery Problems and Their Solutions By Paul W. Grimm, Charles S. Fax, Paul Mark Sandler. Grimm et al also tell us to look at Losey’s paper.
![A party’s ESI privilege log will contain different information, depending on which of these approaches that party uses. For ex- ample, if a party renames its Native Files using a bates-type numbering system, the party's ESI privilege log will list each privileged item by its file name. On the other hand, if “hash values” are used to identify ESI materials, each file will be identified by its hash value. A hash value is a “unique numerical identifier that can be assigned to a file, a group of files, or a portion of a file, based on a standard mathematical algorithm[.]" Lorraine v. Markel American Ins. Co., 241 F.RD. 534, 546 (D. Md. 2007) (citation omitted). “‘Hashing’ is used to guarantee the authenticity of an original data set and can be used as a digital equivalent of the Bates stamp used in paper document production." Id. at 546-47. Put another way, a hash value is a “digital fingerprint akin to a tamper-evident seal on a software pack- age. . . . When an electronic file is sent with a hash mark, others can read it, but the file cannot be altered without a change also occurring in the hash mark.” Williams v. Sprint/United Mgmt. Co., 230 F.RD. 640 (D. Kan. 2005); see also Ralph C. Losey, Hash: The New Bares Stamp, 12 J. TECH. L. & POL’Y l (2007). Id.](http://www.fishandink.com/blog/wp-content/uploads/2015/06/discovery-problems-and-solution.jpg)
In Lorraine v. Markel Am. Ins. Co. (PWG-06-1893, at 25-26 (D. Md. May 4, 2007)) Judge Grimm says that “one method of authenticating electronic evidence under Rule 901(b)(4) is the use of ‘hash values’ or ‘hash marks’ when making documents.” Not surprising Judge Grimm cites Williams v Sprint. (He also cites Managing Discovery of Electronic Information: A Pocket Guide for Judges but that guide does not refer to hash marks.)
There are a few books which provide a glossary with the following:
Hash: An algorithm that creates a value to verify duplicate electronic documents. A hash mark serves as a digital thumbprint.
Cyber Forensics: A Field Manual for Collecting, Examining, and Preserving Evidence of Computer Crimes By Albert Marcella, Jr., Doug Menendez
Matthew Bender Practice Guide: California E-Discovery and Evidence Feb 25, 2015
by Michael F. Kelleher
This definition of hash mark appears to have originated with RenewData’s glossary (in 2005) and was referenced on edrm.net where it got picked up. RenewData later started using this definition:
Hash: an algorithm that creates a value to verify duplicate electronic documents. A hash value serves as a digital thumbprint.
Do you see what they did there?
What are hash marks? Really? # is a hash mark. As in shift + 3 on your keyboard. A hash mark is not the same thing as a hash value.
A New York Times article also refers to hash value as a hash mark but that seems to be an isolated instance.

A search for “cryptographic hash mark” yields results that are all related to the subject of this NYT article.
In short, “hash mark” is not an appropriate substitution for “hash value” but because a paper written by a law student in 1999 referred to the hash mark the term has become embedded in the vernacular of our times.


